
Illustration of our proposed DreamStory framework. This system takes a full narrative text as input, generates vivid visual content, and maintains the consistency of multiple subjects across various scenes within the story.
Illustration of our proposed DreamStory framework. This system takes a full narrative text as input, generates vivid visual content, and maintains the consistency of multiple subjects across various scenes within the story.
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model (DreamStory).
The DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subjects across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene’s subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal guidance. Finally, the MSD uses this multimodal guidance to generate story scenes with consistent multi-subjects.
Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA module ensures detailed appearance consistency with reference images, while MMCA captures key attributes of subjects from their reference text to ensure semantic consistency. Both modules employ masking mechanisms to restrict each scene’s subjects to referencing the multimodal information of the corresponding subject, effectively preventing blending between multiple subjects.
To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations.
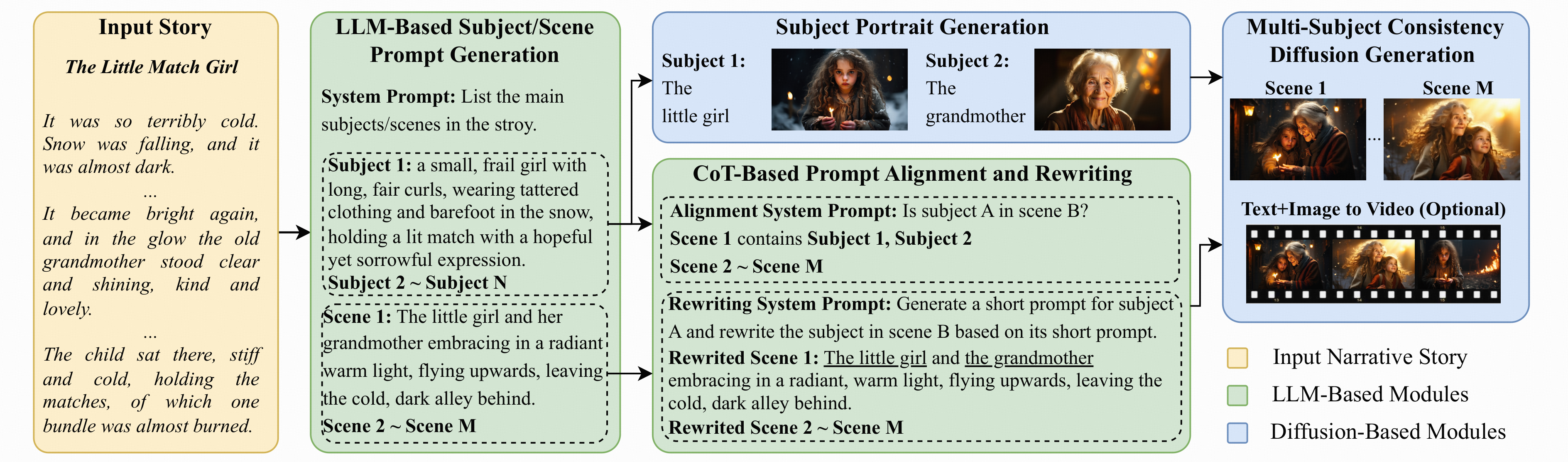
The framework of our proposed DreamStory. Initially, the LLM comprehends a story and generates detailed prompts for key subjects and scenes. These prompts are aligned and rewritten to enhance understanding of the diffusion model, ensuring accurate visual content generation. Subject portraits are then generated based on these prompts, serving as multimodal anchors for maintaining multi-subject consistency and enriching scenes with high-quality visual details, which facilitates subsequent video creation using an I2V model.
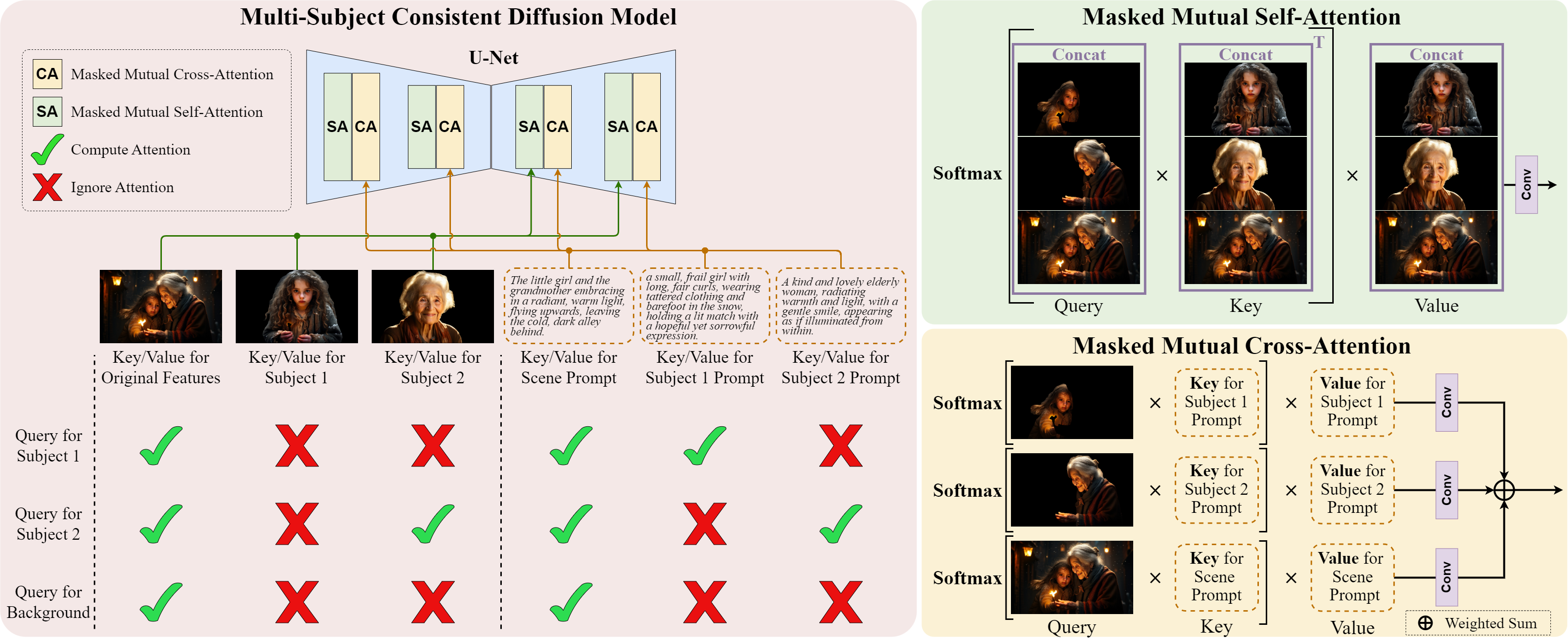
The illustration of our Multi-Subjects consistent Diffusion models (MSD), along with its Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) mechanisms. It uses two subjects as examples and can be extended to any number of subjects. Query, Key, and Value projection in the attention layer have been omitted for ease of presentation.

Qualitative comparisons of our DreamStory with SOTA approaches on the FSS real story benchmark. Ours, MuDI, and ConsiStory utilize the subject image on the bottom-left as the reference image. In contrast, Story Diffusion references the subject image on the bottom-right. Different subjects are indicated with different colors.

Qualitative comparisons of our DreamStory with SOTA approaches on the ChatGPT generated story benchmark. Ours, MuDI, and ConsiStory utilize the subject image on the bottom-left as the reference image. In contrast, Story Diffusion references the subject image on the bottom-right. Different subjects are indicated with different colors.

Qualitative comparisons of our DreamStory with SOTA approaches on the synthetic benchmark. Ours, MuDI, and ConsiStory utilize the subject image on the left as the reference image. In contrast, Story Diffusion references the subject image on the right. Different subjects are indicated with different colors. Our method better maintains consistency across multiple subjects, such as the cat in the first row, the color of the man's suit and the woman's hair in the second row, the hair color of the boy in the third row, and the head of the astronaut in the fourth row.

User Study on DS-500 benchmark. Dominant preferences to our full model are presented, compared with other competitive baselines (a,b, c) and ablation models (d,e). T-I Alignment means text-image relevance.
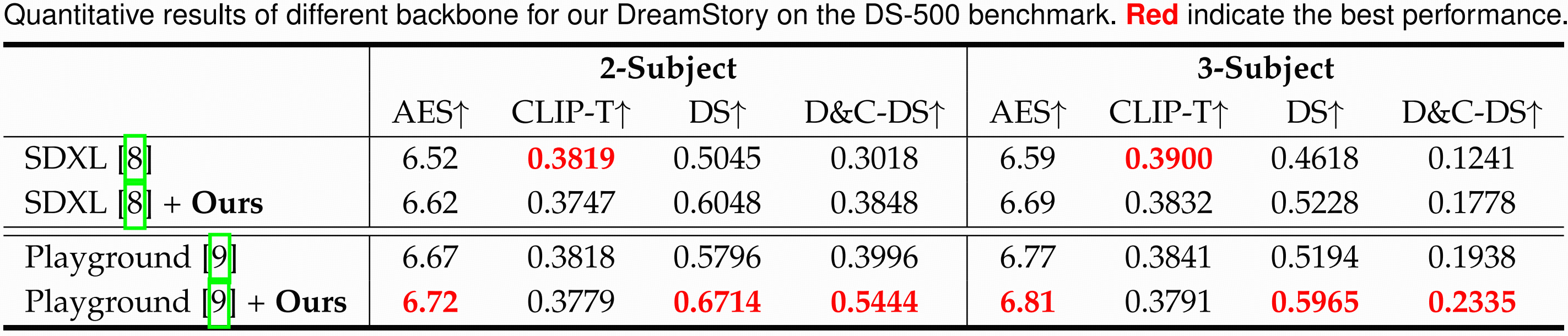
Quantitative results of different backbone for our DreamStory on the DS-500 benchmark. Red indicate the best performance.
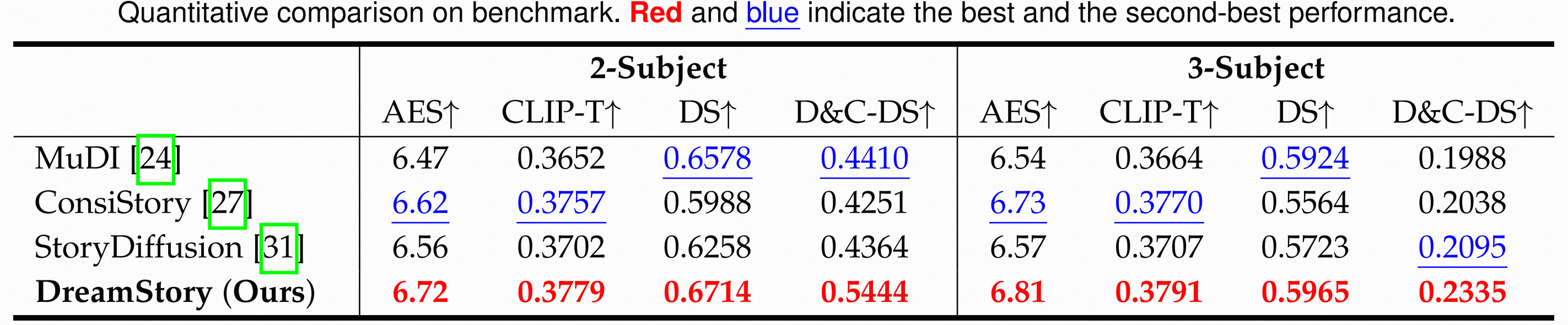
Quantitative comparison on benchmark. Red and blue indicate the best and the second-best performance.
Video Results of the complete story generated by our DreamStory. Turn on the sound for a better viewing experience.
@article{DreamStory,
title={{DreamStory}: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion},
author={He, Huiguo and Yang, Huan and Tuo, Zixi and Zhou, Yuan and Wang, Qiuyue and Zhang, Yuhang and Liu, Zeyu and Huang, Wenhao and Chao, Hongyang and Yin, Jian},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2025},
volume={47},
number={12},
pages={11874-11891},
doi={10.1109/TPAMI.2025.3600149}
}